Strawberry:通用大语言模型之痛
This page is also available in: English
人工智能(AI)领域在过去几年取得了巨大的进步,尤其是大语言模型(LLM)的发展为我们打开了与机器交流的新方式。然而,随着这些模型逐渐深入日常生活和工作应用,一些基础且常识性的问题却暴露出了模型的局限性和困境。
网传,OpenAI 即将发布一款名为 Strawberry 的新型大语言模型。这款模型最为显著的特点在于它能够在面对复杂问题时,先“思考”10~20秒,进行自我检查和反思,然后再给出答案。这与现有的 LLM 模型立即作答的方式有着本质的区别,也似乎透露出 AI 技术发展的新方向。

1. Strawberry:自我检查与反思的新模式
当前已发布的 LLM 模型,在大多数场景中以其快速响应的能力受到好评。这些模型通过先进的算法和大量的数据训练,能够迅速理解并生成回答。然而,面对某些复杂或具有误导性的常识性问题,模型往往会给出让人啼笑皆非的错误答案。比如一个经典的例子:9.11 与 9.8 哪个大?大多数 LLM 模型都会简单地根据数字大小对比,得出小数部分 11 大于 8 的结论,而忽略了小数点。
Strawberry 的设计初衷之一,就是要避免这类错误,在面对类似问题时,先进行“思考”和“反思”,然后再作答,避免机械推理带来的误判。这也是为什么网传 Strawberry 会采取一个不同的策略:它需要花费额外的时间,模拟类似人类思维中的“反思”和“自我检查”过程。这种新的思维模式,意味着它在面对复杂问题时不会立刻作答,而是会对自身的推理过程进行审视,检查是否存在逻辑错误或潜在的误导因素,从而提升答案的准确性。
2. Strawberry 的命名与常识性难题
值得一提的是,为什么 OpenAI 会选择 “Strawberry” 作为这款模型的名字?虽然官方并未给出明确解释,但我们可以从几个著名的 LLM 错误中找到线索。除了前面提到的日期比较错误,另一个有趣的例子是关于英文单词 Strawberry 的问题。当人们问大语言模型:“Strawberry 这个单词中有几个字母 r?” 许多 LLM 竟然会回答有两个 “r”。
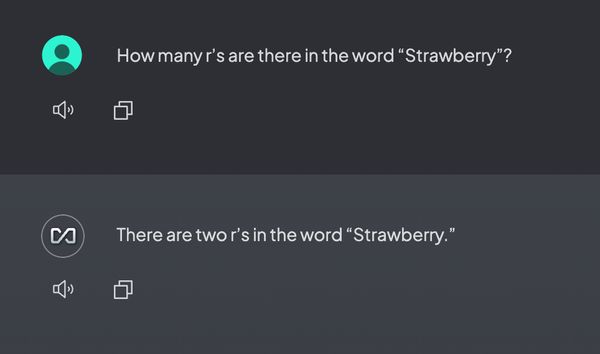
这是因为模型在解析和生成答案时,没有细致地分析和反思,而是根据常见的词汇模式匆忙得出结论。而事实上,只要模型能够多一个计数检查的过程就可以得到正确的答案,这类错误令人始料未及,但也直击了大语言模型的痛点——缺乏反思和自我检查。
3. 反思与检查:AI 推理的未来?
这些常识性问题之所以会成为 AI 模型的“阿喀琉斯之踵”,其根本原因在于模型在推理过程中,缺乏一个反思和检查的机制。目前的大多数 LLM 模型基于概率驱动的语言生成,虽然能够快速做出决策,但没有经过像人类那样的“自我怀疑”与“再确认”的步骤。因此,面对那些逻辑性或复杂推理的问题时,模型可能会做出看似合理但实则错误的判断。
Strawberry 引入了一个额外的“思考时间”,在快速作答之前进行自我检查,模仿人类在回答问题时的慎重思考过程。这种机制不仅仅是为了提升答案的正确率,也是一种全新的推理和决策架构的体现。AI 不再仅仅依赖于概率模型的简单计算,而是尝试在答案生成前,对结果进行二次验证,进而提高应对复杂问题的能力。
4. 迎接挑战:Strawberry 的意义
无论是日期比较问题,还是Strawberry 单词字母数量的问题,都是当前最先进 AI 模型所面临的“陷阱”。这些问题暴露出,尽管 LLM 在处理大规模数据和复杂生成任务上表现优异,但在面对常识性推理时却频频受挫。这不仅是技术上的挑战,更是 AI 未来发展的一个重要拐点。
通过将新模型命名为 Strawberry,OpenAI 似乎在暗示,他们不仅仅意识到了这一问题,更在通过技术进化来应对这些挑战。Strawberry 的出现或将成为 AI 模型发展的一个新里程碑——不仅仅是提升语言理解和生成的能力,更是在推理和决策过程中加入了人类式的反思。
结语
随着 AI 模型在日常生活中的应用日益广泛,其推理能力的极限也不断被测试。OpenAI 即将发布的 Strawberry 模型,似乎是一种全新的尝试:通过引入自我检查和反思机制,突破现有模型在常识性问题上的瓶颈。对于 AI 技术的未来,Strawberry 代表着不仅仅是生成能力的提升,更是一种推理方式的革新,值得我们拭目以待。
本文发布于 2024-09-12,最近更新 2024-09-23。
本文版权归 torchtree.com 网站所有,未经授权不可转载。